

VAE와 GAN은 대표적인 이미지 생성모델입니다. 둘 다 기본적인 원리는 비슷합니다. 잠재벡터 z를 사진으로 생성하는게 목표입니다. 이론적으로 z는 모든 이미지를 표현할 수 있습니다. 하지만 학습 데이터에서는 극히 일부분의 z만 커버합니다. 예를 들어, 학습으로 1%의 z를 배웠다고 가정해보겠습니다. 딥러닝의 일반화를 통해 나머지 99%의 z도 사진으로 변환이 가능합니다.
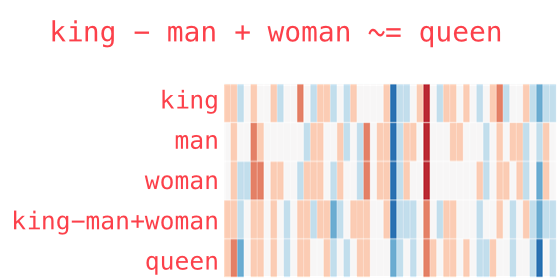
자연어처리에서 워드임베딩은 단어를 벡터로 표현합니다. 그리고 '왕-남자+여자=여왕'처럼 벡터연산으로 새로운 단어를 유추할 수 있습니다. 생성모델 역시 비슷합니다. z만 조작하면 사진이 원하는대로 변형됩니다.
원본사진 z에 안경벡터를 추가하여 모델에 넣으면 안경을 쓴 사진이 나옵니다. 이런 방법을 사용하면 딥페이크, 사진편집, 가상모델 등 다양한 곳에 응용할 수 있습니다.


문제는 특징벡터를 어떻게 추출하는가 입니다. 그중 하나의 방법은 사람이 단 라벨값을 이용하는 것입니다. 모든 사진 데이터에 각 특징이 존재하는지 태그를 붙입니다. 이 사람이 안경을 썼으면 1, 아니면 -1, 이런 식으로 특징값들을 지정합니다.
그다음 특징 라벨이 존재하는 POS와 존재하지 않는 NEG로 사진을 분리합니다. POS와 NEG 사진들의 z를 각각 평균을 내고, POS에서 NEG를 뺍니다. 그러면 그 특징의 벡터만 남게 됩니다. 만약 안경을 쓴 사진들의 z 평균에서 안경을 안쓴 사진들의 z 평균을 빼면, 안경이라는 특징 벡터를 구할 수 있습니다.

이런 특징 추출이 발전하면 매우 미세하게 사진을 조작하게 됩니다. 전신 사진 한 장만 있으면 그 사람의 표정, 동작, 의상 등을 마음대로 변경할 수도 있습니다. 머지 않아 포토샵처럼 GAN샵 같은 프로그램이 대중화될거라 생각합니다.
< 미술관에 GAN 딥러닝 예제 >
- https://github.com/…/…/master/03_06_vae_faces_analysis.ipynb